Número de pasos
El número de pasos dependientes varían según la arquitectura de la máquina. Algunos ejemplos:
- Entre 1956 y 1961, el proyecto IBM stretch proponía los términos Fetch (Lectura), Decode (Decodificación) y Execute (Ejecución) que se convirtieron en habituales.
- La segmentación RISC clásica comprende:
- Lectura de instrucción
- Decodificación de instrucción y lectura de registro
- Ejecución
- Acceso a memoria
- Escritura de vuelta en el registro
- Las microcontroladoras Atmel AVR y PIC disponen cada una de segmentación de dos etapas.
- Muchos diseños incluyen segmentación de 7, 10 e incluso 20 etapas (como es el caso del Pentium 4 de Intel).
- Los núcleos "Prescott" y "Cedar Mill" de la microarquitectura NetBurst de Intel, utilizados en las versiones más recientes del Pentium 4 y sus derivados Pentium D y Xeon, tienen una segmentación de 31 etapas.
- El "Xelerated X10q Network Processor" cuenta con una segmentación de más de 1000 etapas, si bien en este caso 200 de estas etapas representan CPU independientes con instrucciones programadas de forma individual. Las etapas restantes se usan para coordinar los accesos a la memoria y las unidades funcionales presentes en el chip.
Conforme la segmentación se hace más "profunda" (aumentando el número de pasos dependientes), un paso determinado puede implementarse con circuitería más simple, lo cual puede permitir que el reloj del procesador vaya más rápido. En inglés, las segmentaciones de este tipo pueden llamarse superpipelines.
Se dice que un procesador está totalmente segmentado si puede leer una instrucción en cada ciclo. Por tanto, si ciertas instrucciones o condiciones requieren un retardo que impide la lectura de nuevas instrucciones, el procesador no está totalmente segmentado.
2.3.3 Conjunto de instrucciones: características y funciones.
Ante el diseño de un nuevo ordenador de propósito general hay que plantearse la siguiente
cuestión: ¿Qué tipos de instrucciones deben ser incluidos en su conjuntos de instrucciones?
Antes de responder a esta pregunta, analizaremos las características que deben tener los juegos
de instrucciones de las máquinas.
Los conjuntos de instrucciones de las máquinas deben tender a poseer una serie de propiedades,
bastante ideales e imprecisas, que pueden resumirse en las siguientes:
El conjunto de instrucciones de un computador debe ser completo en el sentido de que
se pueda construir un programa para evaluar una función computable usando una cantidad
de memoria razonable y empleando un tiempo moderado, es decir, el número de
instrucciones de ese programa no debe ser demasiado elevado.
Los juegos de instrucciones también tienen que ser eficientes, esto significa que las funciones
más necesarias deben poder realizarse usando pocas instrucciones.
El conjunto de instrucciones de una máquina debe ser regular, es decir debe ser simétrico
(por ejemplo, si existe una instrucción de desplazamiento a la izquierda, debe haber otra
de desplazamiento a la derecha, etc.) y ortogonal, es decir, deben poder combinarse, en
la medida de lo posible, todos las operaciones con todos los tipos de datos y modos de
direccionamiento. En muchas ocasiones, también se le debe exigir a un computador que su juego de instrucciones
sea compatible con modelos anteriores.
Tipos de instrucciones
Una máquina puede llegar a funcionar con un juego de instrucciones muy limitado (recuérdese,
por ejemplo, la máquina de Turing que sólo tiene 4 instrucciones, incluso se han
diseñado máquinas teóricas con menos instrucciones), esto simplificaría mucho los circuitos de
la máquina. Sin embargo, un conjunto de instrucciones demasiado simplificado origina, como
consecuencia, unos programas demasiado complejos e ineficientes. Es necesario encontrar un
compromiso entre la simplicidad del hardware y del software. Un mínimo para llegar a ese
compromiso se consigue con los tipos de instrucciones siguientes:
Instrucciones de transferencia de datos.
Instrucciones aritméticas.
Instrucciones lógicas.
Instrucciones de control del flujo del programa (bifurcaciones, bucles, procedimientos,
etc.)
Instrucciones de entrada y salida.
En los apartados siguientes iremos viendo con detalle algunos de estos tipos de instrucciones.
Si bien es cierto que el conjunto de instrucciones debe de cumplir unos mínimos para conseguir
una mínima eficiencia en los programas, también se verá que ésta no se aumenta indefinidamente
al incrementar el número de instrucciones de la máquina.
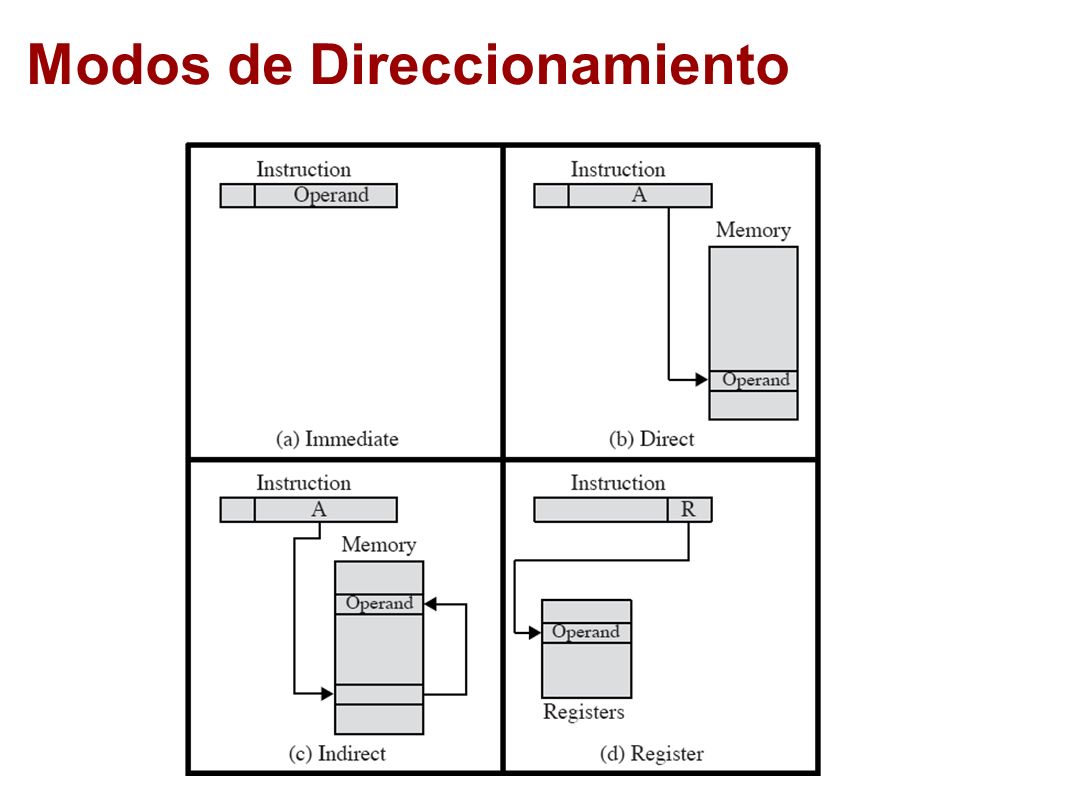
2.3.4 Modos de direccionamiento y formatos
Son las diferentes maneras de especificar un operando dentro de una instrucción. Un modo de direccionamiento especifica la forma de calcular la dirección de memoria efectiva de un operando mediante el uso de la información contenida en registros dentro de una instrucción de la máquina.
Direccionamiento implícito
Depende solamente de la instrucción, es decir, la instrucción no lleva parámetros.
Particularmente en instrucciones que no accesan memoria, o bien que tienen una forma específica de accesarla.
Ejemplos: PUSHF, POPF, NOP
Modo registro
Usa solamente registros como operandos
Es el más rápido, pues minimiza los recursos necesarios (toda la información fluye dentro del EU del CPU)
Ejemplo:
MOV AX, BX
Modo inmediato
Tiene dos operandos: un registro y una constante que se usa por su valor.
El valor constante no se tiene que buscar en memoria, pues ya se obtuvo al hacer el “fetch” de la instrucción.
Ejemplo:
MOV AH, 9
Modo directo
Uno de los operandos involucra una localidad específica de memoria
El valor constante se tiene que buscar en memoria, en la localidad especificada.
Es más lento que los anteriores, pero es el más rápido para ir a memoria, pues ya “sabe” la localidad, la toma de la instrucción y no la tiene que calcular.
Ejemplo:
MOV AH, [0000]
MOV AH, Variable
Estas dos instrucciones serían equivalentes, si Variable está, por ejemplo, en la localidad 0 de memoria. En la forma primitiva del lenguaje de máquina, como el primer ejemplo, se tiene que indicar “mover a AH el contenido (indicado por los corchetes), de la localidad 0 de los datos (lo de los datos es implícito). El lenguaje Ensamblador, sin embargo, nos permite la abstracción del uso de variables, pero como una variable tiene una localidad determinada en memoria, para el procesador funciona igual. La única diferencia consiste en que el programador no tiene que preocuparse por la dirección, ese manejo lo hace automáticamente el Ensamblador.
Modo indirecto
Se usan los registros SI, DI como apuntadores
El operando indica una localidad de memoria, cuya dirección (sólo la parte desplazamiento) está en SI o DI.
Es más lento que los anteriores, pues tiene que “calcular” la localidad
Ejemplos:
MOV AL, [SI]
MOV BL, ES:[SI] ; Aquí se dice que se usa un “segment override”, donde se indica que en vez de usar el segmento de datos por defecto, se use en su lugar como referencia el segmento extra.
Modo indexado de base
Formato:
[
BX o BP
+ SI o DI (opcionales)
+ constante (opcional)
]
BX o BP indica una localidad base de la memoria
A partir de BX o BP, se puede tener un desplazamiento variable y uno constante
La diferencia es el segmento sobre el que trabajan por defecto:
BX por defecto en el segmento de datos
BP por defecto en el segmento de pila.
Ejemplos:
MOV AX, [BX]
MOV DX, [BX+2]
MOV CX, [BX+DI]
MOV DL, [BX+SI+3]
Ref:
Stallings William, Organización y arquitectura de computadores, Madrid, Pearson Educación, 2005.
José Ignacio Hidalgo. Arquitectura de Computadores y Automática. Unversidad Complutense de Madrid (Spain). 2009


:max_bytes(150000):strip_icc():format(webp)/Placabaseychipset-5b0ac8b41d64040037074a3c.jpg)